

Last week I was installing a physical Windows Server 2019 server (not every day you install Windows on a pshysical server, I know) for a Veeam installation. The reason for the physical approach was to gain performance and not to hit the maximum VMDK size in vSphere as a whole bunch of local disks are used as backup repository.
Anyhow, enough background talking.
The server is connected both to the environments management network, but also directly to the SAN switches via fiber to be able to use Direct SAN Access (i.e. to fetch the VMs data directly from the SAN without passing vSphere). In addition to that, the server is also connected to a separate data network for offsite backup copy.
During the setup, I was trying out NIC teaming in Windows for the first time (not a thing you use when setting up Windows Server as a virtual machine). I connected the special data network to two diffrent core switches and configured NIC teaming as switch independet with both adapters active:
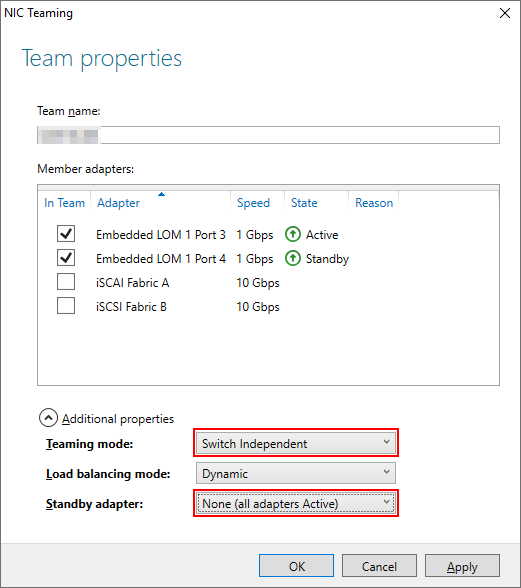
At the other end (the backup copy repository), an HP StoreOnce appliance, I configured bonding (kind of the same as NIC teaming). Same procedure here; connected the StoreOnce to two diffrent core switches and configured the bond to use both adapters in a load balancing:
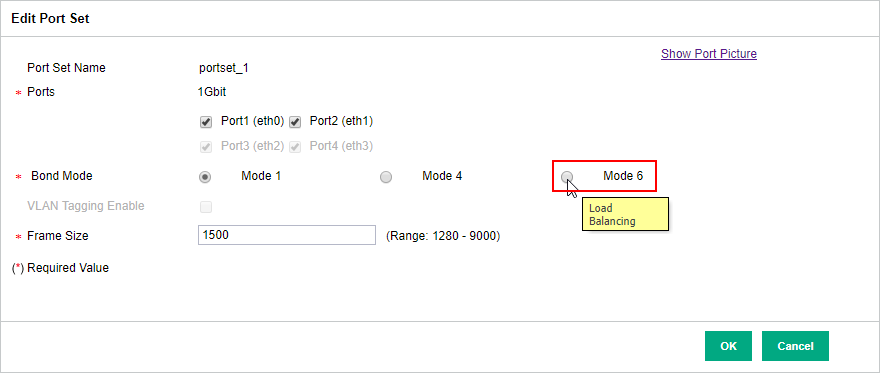
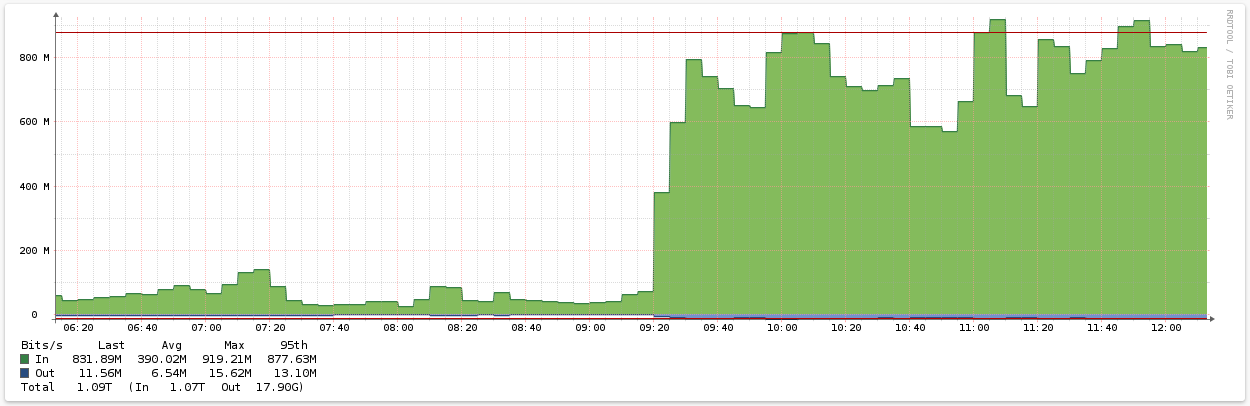
So now I have a totaly redundant solution, right? Let’s fire up a backup copy job! Said and done. The morning after I checked the status of the job – 20 % and full of error “OSCLT_ERR_INTERNAL_ERROR. Failed to write data to the object”. I also noticed that the server was not using more then about 10-20 Mbit/s of bandwith out of a gigabit in total.
I googled a bit about the diffrent bonding and NIC teaming modes and how they work. Not to hard to guess, in load balancing and all adapter active mode, they alter the packets between the switch ports. Maybe Veeam, Windows, StoreOnce, or the nerwork itself isn’t too good to handle this, I thought.
To test out my theory, I changed the bonding mode on the StoreOnce to failover only instead, meaning that all packets will travel though one switch port only and only change if the link goes down:
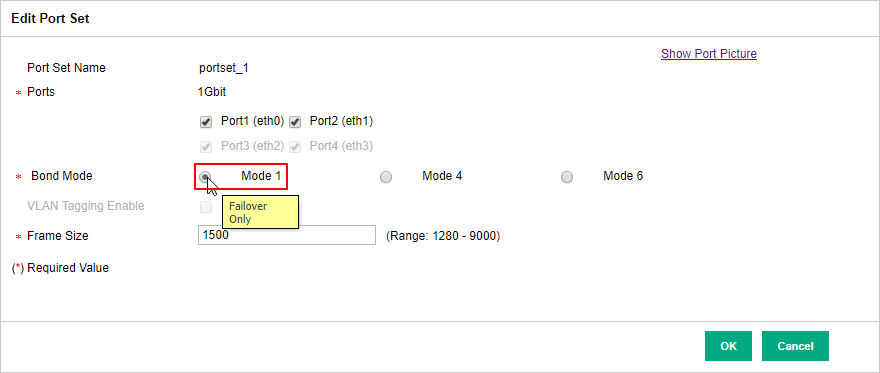
After this, the error in Veeam disappeared but the slow transfer speed remained. As I was on to something, I continued my testing by also changing the NIC teaming mode in Windows to active/standby by choosing a standby adapter:
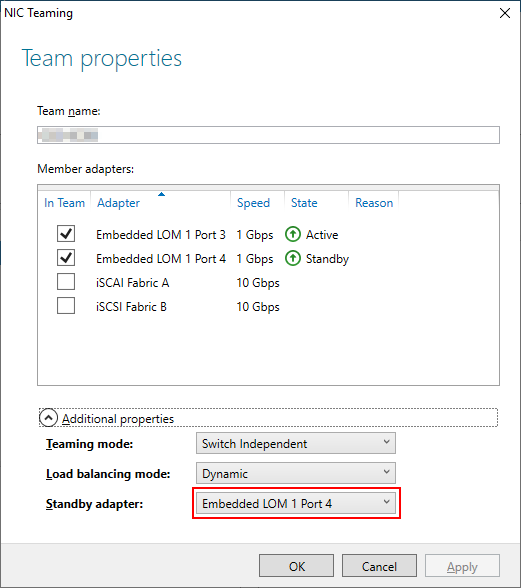
Boom! The transfer speed changed dramatically:
To improve the transfer speed even more, I turned off the limit on the StoreOnce backup repository in Veeam:
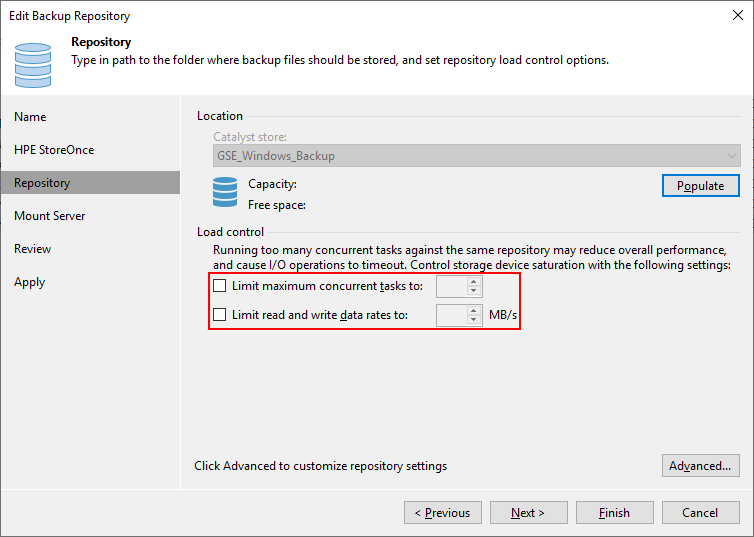
Normally, you should never turn off the limit as it could result in some serious bottlenecking. I read somewhere that a general guideline is to have the same limit on the repository as you have in your proxy (i.e. the number of cores you have in your server). But for a StoreOnce, Veeam is able to tell via the Catalyst how many tasks it can run simultaneously.
Nice, eh?


